近年来,越来越多的研究人员正在开发基于人工神经网络的模型,该模型可以通过称为强化学习的技术进行训练。RL要求训练人类智能体在表现良好时通过给予“奖励”来解决各种任务(例如,正确分类图像)。
到目前为止,大多数基于人工神经网络的模型都是通过在线RL方法进行训练的,其中,智能体的任务是与网络虚拟环境交互设计,完全可以学习。然而,这种方法可能非常昂贵、耗时且效率低下。
最近,一些研究探索了离线训练模式的可能性。在这种情况下,人类智能体通过分析固定数据集来学习完成给定的任务,因此它们不会主动与虚拟环境交互。虽然离线RL方法在一些任务中取得了可喜的成果,但不允许代理实时学习。
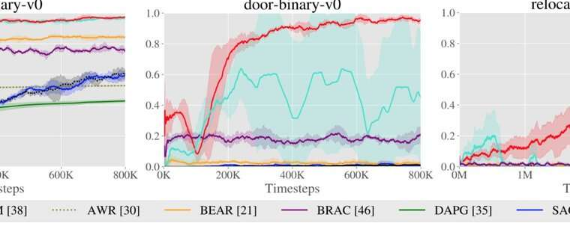
加州大学伯克利分校的研究人员最近引入了一种新算法,该算法通过使用在线和离线RL方法进行训练。该算法是在arXiv上发表的一篇论文中提出的。它原本是针对大量的线下数据进行训练的,但同时完成了一系列的在线训练实验。
进行这项研究的研究人员之一Ashvin Nair告诉TechXplore:“我们的工作重点是我们在现实世界中的机器人环境中不断面临的两种情况之间的情况。”“通常,在尝试解决机器人技术问题时,研究人员会有一些先验数据(例如,一些关于如何解决任务的专家演示或您上次执行的实验的一些数据),并希望使用先验数据来部分解决任务,但随后他们可以微调解决方案,以很少的交互来掌握它。”
回顾过去的RL文献,奈尔和他的同事意识到,当先进行离线训练,然后进行在线微调时,以前开发的模型并不有效。这通常是因为他们学习太慢,或者在训练中没有充分利用离线数据集。